Why GreptimeDB
GreptimeDB 是一个云原生、分布式且开源的时序数据库,旨在处理、存储和分析海量的指标(metrics)、日志(logs)和事件(events)数据(链路 traces 也在计划中)。 关于更多 GreptimeDB 创立背景和所能解决的行业痛点分析,欢迎先阅读这篇文章。
我们的解决方案能更高效地管理海量的时间序列数据,并且能轻松处理时序数据的写入/查询和分析的混合负载需求。无论你的系统是在本地运行还是在云端,GreptimeDB 都可以轻松处理任何规模的负载。基于过去的经验,我们有信心为用户提供任何符合其需求的解决方案和服务。
我们在设计和开发 GreptimeDB 时遵循以下原则:
- 统一指标、日志和事件: 时序数据库应该涵盖广义的时序数据,能同时处理指标(metrics)、日志(logs)和事件(events)等时序数据,简化架构并降低用户的部署成本和使用成本。
- 云原生:从设计 GreptimeDB 的第一天起,其就被定位为一款完全利用云的基础设施和能力来运行和服务的云原生数据库,因此具有出色的可扩展性和容错性。
- 用户友好:我们明白开发者体验至关重要,GreptimeDB 的设计关键原则是对开发者友好。这不仅体现在开发、部署和运营方面,在与数据生态系统的无缝兼容性,以及不断完善的文档和社区指南方面,都无一不体现了 GreptimeDB 用户友好的特性。
- 高性能:处理时间序列数据的特性之一就是大规模的数据摄取、查询和分析。在高并发场景下依然持续进行性能优化也是我们设计 GreptimeDB 时的核心原则之一。
- 灵活的架构:通过抽象良好的分层和封装隔离,GreptimeDB 的部署形式可以满足从嵌入式、单机版、传统集群到云原生的各种环境。
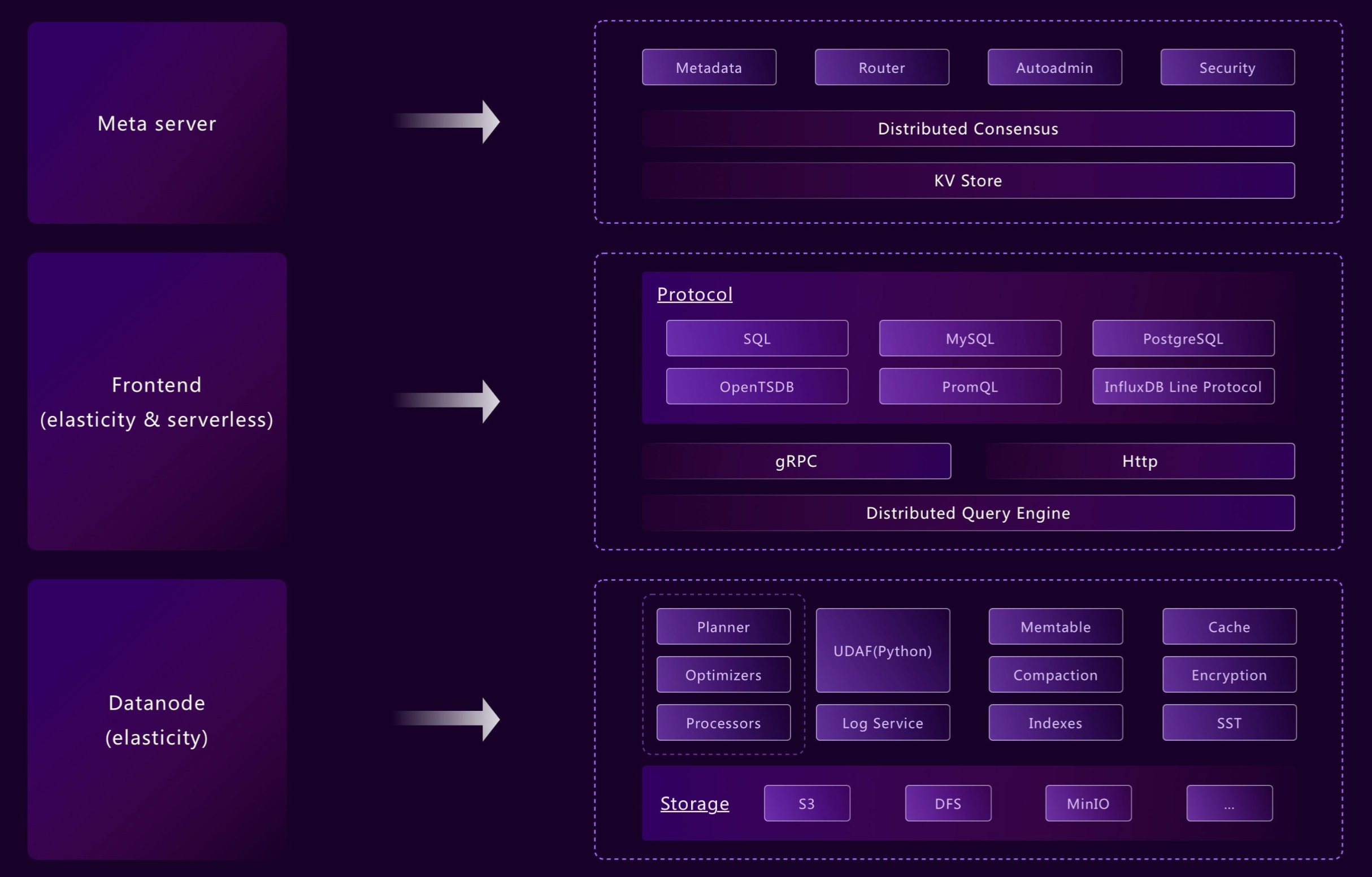
接下来,我们将逐一展开说明下这些设计原则。
统一指标、日志和事件
通过时序表的模型设计、SQL 的原生支持,以及存算分离架构带来的混合负载,GreptimeDB 可以同时处理指标、日志和事件,增强不同时间序列数据之间的关联分析,并简化用户的架构、部署和 API。
阅读SQL 示例以获取详细信息。
云原生
GreptimeDB 专为云而生,充分利用云的优势,如弹性、可扩展性和高可用性。
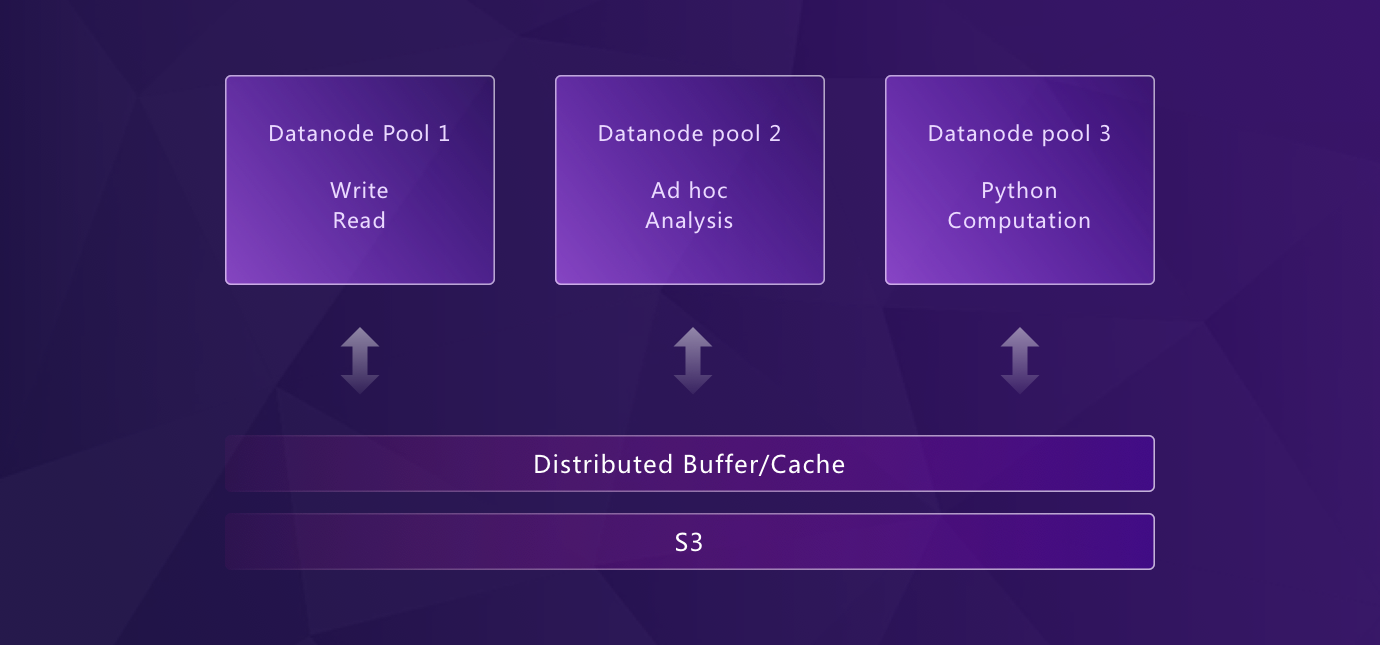
存算分离
在云中分离存储和计算资源有几个好处:
- 存储和计算可以根据需求轻松地、独立地进行扩展
- 数据可以写入价格较低的云存储服务,如阿里云 OSS、 AWS S3 或 Azure Blob Storage
- 可以使用 Serverless 容器自动且弹性地扩展计算资源
算算分离
算算分离能将不同工作负载的计算资源隔离开:
- 隔离不同的计算资源,以避免因数据摄取(Data Ingestion)、实时查询以及数据压缩或降采样等任务产生的资源竞争
- 在多个应用程序之间共享数据
- 根据需求提供无限的并发扩展性
用户友好
Time-Series Table,schemaless 设计
「GreptimeDB」结合了 Metric (Measurement/Tag/Field/Timestamp) 模型和关系数据模型(表),提供了一个名为 Time-Series Table 的新数据模型,该模型以行和列的形式呈现数据,将 Metric 中的标签和字段映射到列上,同时通过 Time Index 约束来指定时间索引所在列。
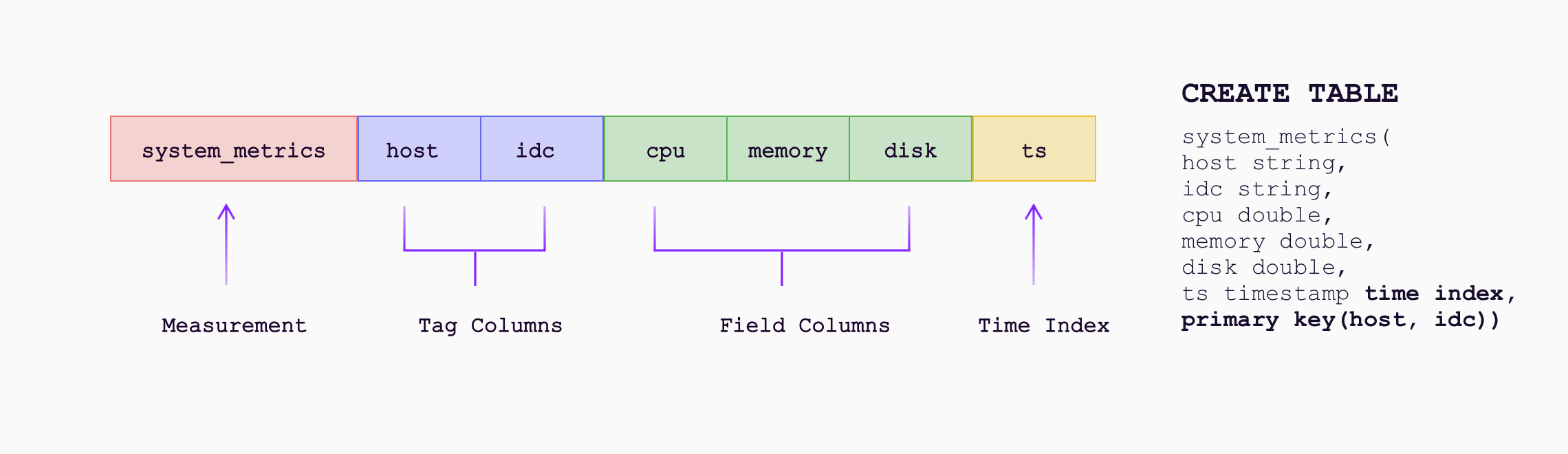
然而,在我们的设计中,对 Schema 的定义并非强制性的,而是更偏向于像 MongoDB 这样的数据库的 Schemaless 方式。当数据被写入时,表将被动态地自动创建,新的列(标签和字段)将也会自动被添加进表中。
PromQL、SQL 和 Python
GreptimeDB 支持 PromQL 和 SQL,它们都依赖于同一查询引擎。该引擎采用向量化执行,这种执行是并行和分布式的。
PromQL 是可观测领域流行的查询语言,用户可以通过 PromQL 查询汇总由 Prometheus 提供的实时的时序数据。与 SQL 相比,它在使用 Grafana 进行可视化和创建警报规则时要简单得多。GreptimeDB 通过解析 PromQL 转化为查询计划,然后由查询引擎优化和执行,从而原生地、高性能地支持 PromQL。
SQL 在分析时间跨度大或来自多个表的数据方面更为强大,例如多表连接查询。SQL 也方便于数据库管理。
Python 在数据科学家和 AI 专家中非常流行,GreptimeDB 允许在数据库中直接运行 Python 脚本。用户可以编写 Python 自定义函数(UDF)并使用 DataFrame API 来加速数据处理。
易于部署和维护
为简化部署和维护流程,GreptimeDB 为用户提供了 K8s operator、命令行工具、内嵌式仪表板以及其他有用的工具,方便轻松配置和管理自己的数据库。如果你需要全托管的云服务,我们也提供了基于 GreptimeDB 的格睿云 GreptimeCloud 数据库云服务方案。
易于集成
GreptimeDB 支持多种协议,包括 MySQL,PostgreSQL,InfluxDB�,OpenTSDB,Prometheus RemoteStorage 和高性能的 gRPC 等标准开放协议,尽可能的降低数据库接入门槛。此外,我们还为各种编程语言提供了 SDK,例如 Java,Go,Erlang 等。我们持续集成和连接生态系统中的开源软件,以提升开发者的体验。
高性能
就性能优化而言,GreptimeDB 利用 LSM Tree、数据分片和 基于 Quorum 的 WAL 设计等不同技术,来解决大规模时间序列数据的写入工作。
GreptimeDB 还通过列式存储、自适应压缩算法和智能索引,来降低存储成本,并解决时间序列数据的高基数问题。
强大而高效的查询引擎支持向量化执行,查询可以充分利用索引并分布式并行执行。
灵活的架构
通过模块化和分层设计,不同的模块和组件可以独立地开启、组合或分离。例如,我们可以将 Frontend、Datanode 和 Metasrv 合并为一个独立的二进制文件,并且我们也可以独立地为每个表启用或禁用 WAL。
这种灵活的架构设计让 GreptimeDB 能在使用相同的 API 编程接口和控制面的条件下,满足从边缘到云各种场景中的部署和使用需求。
小结
随着时间序列数据的管理和分析需求不断增长,我们相信 GreptimeDB 能够提供一种高效、可扩展和��用户友好的解决方案。我们将在 6 月初推出分布式可用的版本 v0.3,无论你的应用场景是什么,我们都有信心为您提供满足需求的服务,也期待任何反馈和建议,以便我们不断改进我们的产品和服务。